Reading Data¶
Introduction¶
The first task in any data analysis program like CurveExpert Professional is to read or import your data into the software. For this, CurveExpert Professional provides a robust file import mechanism, which can be accessed simply by choosing File->Open. You can read in both native CurveExpert files (.cxp) and generic data files in text format.
Note
To be able to choose files with extensions other than .cxp, you must select the appropriate extension in the bottom right corner of the file choosing dialog.
Most of the time, the data to be read in is contained within a text file of some sort, with headers and comments interspersed. CurveExpert Professional tries to make the job of importing this data as easy and painless as possible. The file import intelligently examines your raw file in order to find the data, as well as finding column headers for that data, if present.
Raw file import¶
To read in a text file (common extensions are .dat and .txt, but can be anything that you choose), simply choose File->Open, and then the filename. Alternatively, drag and drop the file to the CurveExpert Professional spreadsheet. The file import window will display, as follows:
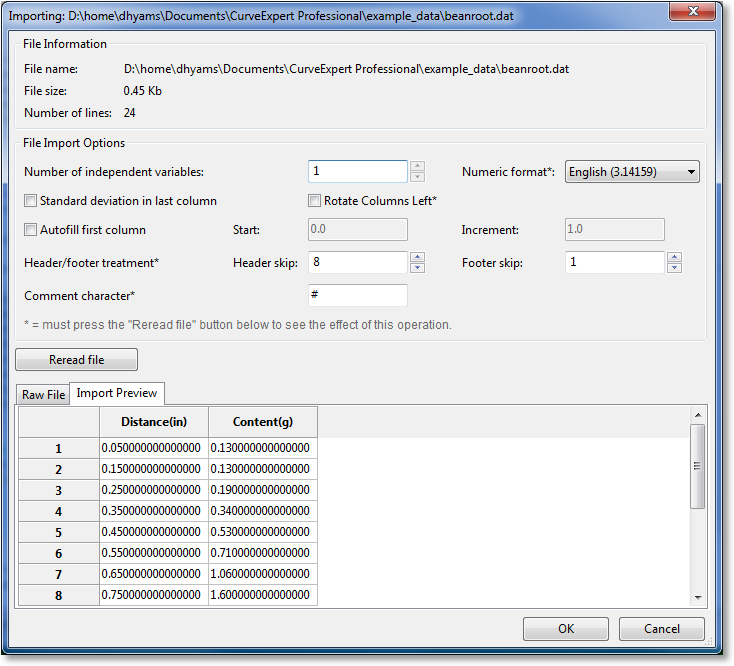
Basic information about the file is shown at the top of the window, where the complete path to the file, file size, and the number of lines detected in the file is displayed. The middle section of the window is where you set parameters necessary for reading in the file. Most of the time, default options are appropriate, and there is not much more to do except to glance at the spreadsheet preview in the bottom third of the window, and click the OK button. However, in cases where the defaults are not appropriate, there are a range of settings you can manipulate to read your file in successfully.
Number of independent variables¶
First, the number of independent variables must be set. CurveExpert Professional normally guesses the number of independent variables to be the number of columns detected in your file minus one. You may change this setting if the default is not correct. Initially, in the absence of any column labels in the file, the independent variables are always called X1, X2, X3, and so on, and the dependent variable is called Y. The result of your operation is shown instantly in the spreadsheet preview.
Note
CurveExpert Professional always expects the independent variable column(s) to be to the left of the dependent variable column.
Numeric format¶
By default, the numeric format is set according to the settings in Edit->Preferences->Localization (see Localization). The two available settings are English (use dots for decimals) and European (use commas for decimals). Select the appropriate numeric format for your file.
Standard deviation in last column¶
If the last column of your dataset is standard deviation data, make sure to check the “standard deviation in last column checkbox. A typical situation is that, on import of a three column dataset, CurveExpert guesses that there are two independent variables and no standard deviation data. To remedy the situation, simply set the number of independent variables to 1, which will leave the last column unassigned. Then, select Standard deviation in last column The result of your operation is shown instantly in the spreadsheet preview.
Rotate columns left¶
Some raw datasets list the dependent variable first. If this is the case, checking Rotate columns left will shift the data in the first column to the last, moving all other columns to the left. This is the ordering that CurveExpert Professional expects (independent variables first, and the dependent variable following). For a two column dataset, this operation is equivalent to swapping the columns. To see the effects of your choice here, the Reread file button must be pressed.
Autofill¶
Sometimes, the independent variable is implied by the ordering of the data. If you would like to generate the first column of data as a simple range and increment, select Autofill first column, and then choose the starting value and increment between each data point. The result of your operation is shown instantly in the spreadsheet preview. The fill is computed as follows:

where i is the point id (starting at zero for the first point),  is the starting value input, and
is the starting value input, and  is the increment input.
is the increment input.
Comment character¶
Most data files have comments interspersed throughout them, sometimes in the middle of the data. In order to skip these comments, the character that designates the comment must be specified. In the data file, then, anything that appears after a comment character is ignored. Common comment characters are ‘#’ and ‘%’.
Refreshing the preview¶
If rotating columns or changing the header/footer treatment, you must press the Reread file button to refresh the preview.
File import preview and raw file preview¶
The file import preview shows the result of the reading of the file, augmented by the current settings discussed above. This preview shows you exactly what CurveExpert Professional will read and place in the main spreadsheet.
The raw file preview shows you a copy of the file, with no modification, so that you can see the contents. Line numbers are annotated on the left, the the header and footer skip settings are shown by dimming the areas of the file that are masked away by these settings.
Column Labels¶
CurveExpert Professional attempts to detect the labels of your columns, such that they are correctly read into the software. To detect the column labels, the file reader examines one line above the skipped header, if such a line exists. In other words, if the header skip is set to 10, line 10 is examined for the column labels. First, the line is trimmed of any white space and comment characters, and then broken into individual tokens. If the number of items on this line is the same as the detected number of columns, these tokens are treated as the column names, as long as they “look like” names. To look like a name, the labels must begin with an alphabetical character, and only contain legal punctuation “()+-*”. So, your data file can look something like this:
Comments at the top of the file are automatically
ignored by the file reader, because
it can tell
that there is no numeric data there.
# or you can comment with a designated comment character
time(s) voltage(volts)
1.0 4.5
2.0 4.23
3.2 4.1
In the example above, the column labels will be automatically detected as “time(s)” and “voltage(volts)”.
Other file metadata¶
To force the localization of a given text file, see File overrides for the required header information.
Finishing¶
When the file import preview looks like the desired dataset, simply hit OK; your data will be read and placed into the main spreadsheet.
CurveExpert Professional files¶
CurveExpert Professional files contain the data, results, graphs, and notes (notes are available in CurveExpert Pro only). To save a .cxp file, simply choose File->Save or File->Save As as appropriate. Correspondingly, to read a .cxp file, choose File->Open.
These files are portable across platforms (Mac, Windows, and Linux), so you can read a file in on a Mac that was generated in Windows, for example. Also, .cxp files are compatible between CurveExpert Professional and CurveExpert Basic 2.0 or later. CurveExpert Basic can read CurveExpert Pro files, and vice versa.
Also, if a particular model or function is saved as a result in a .cxp file and it is not present on the system reading the file, the model/function will automatically be created on your behalf. This newly created model/function will then be available for use in the “Imported” family, and will appear appropriately in the Nonlinear model or function pickers.