
Given a set of data points, often called “observations,” a common need is to condense the data by fitting it to a model in the form of a parametric equation. This “model equation” can be anything that the user desires – it can range from a simple polynomial to an extremely complex model with many parameters. One important consideration in selecting an appropriate model is the underlying law that the data represents. Optimally, the model should be chosen to reflect that law so that the parameters in the curve fit have physical interpretation and meaning.
Data modeling may be performed by several techniques: interpolation, regression, or data smoothing. Interpolation and regression are the types supported by CurveExpert. Interpolation guarantees that the fitted curve will pass through each and every data point. Regression simply ensures that the “merit function”, which is an arbitrary function that measures the disagreement between the data and the model, is minimized. In this approach, the model parameters are adjusted until the merit function becomes as small as possible. One of the features of CurveExpert is the large number of nonlinear regression models that are available. This type of model is the most commonly used in real-world applications.
All linear regressions are accessible in the first half of the “Apply Fit” menu.
Models which consist of a linear combination of a particular set of functions Xk are called linear models, and linear regression can be used to minimize the difference between the model and data. The general form of this kind of model is
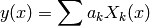
where Xk(x) are fixed functions of x that are called the basis functions, and ak are the free parameters. Note that “linear” refers only to dependence of the model on the parameters ak; the functions Xk(x) may be nonlinear. Minimization of the above linear model is performed with respect to the merit function
![S(a) = \sum_{i=1}^n \left [ y_i - \sum_{k=1}^{np} a_k X_k(x_i) \right ]^2](_images/math/6a4c08389206060ee37a9c5d7b6545987e5ccd35.png)
The minimum of the above equation occurs where the derivative of S with respect to the parameters disappears. Substituting the linear model into this function, taking the first derivative, and setting this equal to zero gives the normal equations that can be solved directly for the parameters ak.
In CurveExpert, all of the linear models implemented are linear combinations of xn. These models are listed below:
For a polynomial regression, you must supply what degree of polynomial that you would like; CurveExpert will prompt you for that information. Polynomials usually tend to give decent curve fits to almost any data set, but higher order polynomials (as a rule of thumb, over 9) tend to oscillate badly. Also, polynomials offer no insight into the model that governs the data.
Note that you may not choose a polynomial degree greater than or equal to the number of points in the data set minus one. A polynomial degree equal to the number of points in the data set minus one is simply interpolation, and that type of curve fitting can be obtained via the Interpolation menu. Degrees greater than the number of data points cause an overconstrained problem, to which the solution is undefined. Note also that you may not choose a polynomial degree of one or two; use the built-in linear and quadratic curve fits instead. In short, the polynomial degree that you can enter in this dialog box is limited to 2 < degree < n-2.
All nonlinear regressions are accessible in the last half of the “Apply Fit” menu. These models include the CurveExpert built-in models, as well as any user defined models that you have designed.
This program uses the Levenberg-Marquardt method to solve nonlinear regressions. This method combines the steepest-descent method and a Taylor series based method to obtain a fast, reliable technique for nonlinear optimization. This statement will be repeated later, but can bear stating at the beginning of this discussion: neither of the above optimization methods are ideal all of the time; the steepest descent method works best far away from the minimum, and the Taylor series method works best close to the minimum. The Levenberg-Marquardt (LM) algorithm allows for a smooth transition between these two methods as the iteration proceeds. In general, the data modeling equation (with one independent variable) can be written as follows:
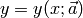
The above expression simply states that the dependent variable y can be expressed as a function of the independent variable x and vector of parameters a of arbitrary length. Note that using the ML method, any nonlinear equation with an arbitrary number of parameters can be used as the data modeling equation. Then, the merit function we are trying to minimize is
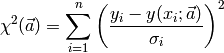
where N is the number of data points, 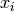 denotes the x data points,
denotes the x data points,
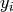 denotes the y data points, si is the standard deviation
(uncertainty) at point i, and
denotes the y data points, si is the standard deviation
(uncertainty) at point i, and 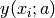 is an arbitrary nonlinear
model evaluated at the ith data point. This merit function simply
measures the agreement between the data points and the parametric
model; a smaller value for the merit function denotes better
agreement. Commonly, this merit function is called the chi-square.
is an arbitrary nonlinear
model evaluated at the ith data point. This merit function simply
measures the agreement between the data points and the parametric
model; a smaller value for the merit function denotes better
agreement. Commonly, this merit function is called the chi-square.
Now, we will take a step back to provide a framework of optimization methods. From the area of pure optimization, which will not be explained here, two basic ways of finding a function minimum are a Taylor series based method and the steepest-descent method. The Taylor series method states that sufficiently close to the minimum, the function can be approximated as a quadratic. Without detailed explanation of that method, a step from the current parameters a to the best parameters amin can be written as
![\vec a_{min} = \vec a_{cur} + H^{-1} \left [ - \Delta \chi^2 ( \vec a_{cur}) \right ]](_images/math/fc2849ab1c5cf898eba0e16c0fc00de32279095b.png)
where H is the Hessian matrix (a matrix of second derivatives). If the approximation of the function as a quadratic is a poor one, then we might instead use the steepest-descent method, where a step to the best parameters from the current parameters is
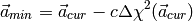
This equation simply states that the next guess for the parameters is a step down the gradient of the merit function. The constant c is forced to be small enough that a small step is taken and the gradient is accurate in the region that the step is taken.
Since we know the chi-square function, we can directly differentiate to obtain the gradient vector and the Hessian matrix. Taking the partial derivatives of the merit function with respect to a gives
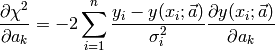
To obtain the Hessian matrix, take the gradient of the gradient above (so that we have a matrix of partial second derivatives):
![\frac{\partial^2 \chi^2}{\partial a_k \partial a_l} = -2 \sum_{i=1}^n \left [ \frac{1}{\sigma_i^2}\frac{\partial y(x_i;\vec a)}{\partial a_k} \frac{\partial y (x_i; \vec a)}{\partial a_l} - \frac{y_i - y(x_i; \vec a)}{\sigma_i^2} \frac{\partial^2 y (x_i; \vec a)}{\partial a_l \partial a_k} \right ]](_images/math/672faffe0bbd2bbafed461c19ce73b1a3b3071bd.png)
Now, for convenience, define the gradient vector and the curvature matrix as
![G_k = -\frac{1}{2} \frac{\partial \chi^2}{\partial a_k} = \sum_{i=1}^n \left [ \frac{y_i - y(x_i; \vec a)}{\sigma_i^2} \frac{\partial y (x_i; \vec a)}{\partial a_k} \right ]](_images/math/91e23b47c09af90fdf2c5a2ead692469c41c86d5.png)
![C_{kl} = \frac{\partial^2 \chi^2}{\partial a_k \partial a_l} = \sum_{i=1}^n \left [ \frac{1}{\sigma_i^2}\frac{\partial y(x_i;\vec a)}{\partial a_k} \frac{\partial y (x_i; \vec a)}{\partial a_l} \right ]](_images/math/f68676e3074bc5eed81cf356b00fd86b5edf60a7.png)
[Note that the second derivative term in C will be ignored because of two reasons: it tends to be small because it is multiplied by (y-yi), and it tends to destabilize the algorithm for badly fitting models or data sets contaminated with outliers. This action in no way affects the minimum found by the algorithm; it only affects the route in getting there.] So, the Taylor series method (inverse Hessian method) can be written as the following set of linear equations:
![\sum_{k=1}^{np} C_{kl} \delta a_l = G_k [1]](_images/math/fbc0df9084067057e20ba589ac47a55fde96df77.png)
where NP is the number of parameters in the model that is being optimized. This linear matrix will be our workhorse for this method after some modification; it can be solved for the increments da that, when added to the current approximation for the parameters, gives the next approximation. Likewise, we can substitute our “convenient” definitions into the steepest descent formula to obtain
![\delta a_l = c G_l [2]](_images/math/875ad5cdaf93af6aa5ad11b705f614c42c72b7f8.png)
Neither of the aforementioned optimization methods are ideal all of the time; the steepest descent method works best far away from the minimum, and the Taylor series method works best close to the minimum. The Levenberg-Marquardt (LM) algorithm allows for a smooth transition between these two methods as the iteration proceeds.
The first issue in deriving the LM method is to attach some sort of
scale to the constant c in the steepest-gradient method (equation
2). Typically, there is no obvious way to determine this number,
even within an order of magnitude. However, in this case, we have
access to the Hessian matrix; examining its members, we see that
the scale on this constant must be 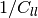 . But, that still may be
too large, so let’s divide that scale by a nondimensional factor
(l) and plan on setting this much larger than one so that the step
will be reduced (for safety and stability).
. But, that still may be
too large, so let’s divide that scale by a nondimensional factor
(l) and plan on setting this much larger than one so that the step
will be reduced (for safety and stability).
The second issue to formulate the LM method is noting that the steepest-descent and Taylor series methods may be combined if we define a new matrix Mij by the following:
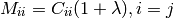
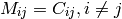
This matrix combines equations [1] and [2] into a convenient and compact form. So finally, we have a means of calculating the step da in the parameters by the following system of linear equations:
![\sum_{k=1}^{np} M_{kl} \delta a_l = G_k [3]](_images/math/7627b46c4dc5a6fd6f25563971143eda9cd2387e.png)
Note that when l is large, the matrix M is forced to be diagonally dominant; consequently, the above equation is equivalent to the steepest descent method (equation 2). Conversely, when the parameter l goes to zero, the above equation is equivalent to the Taylor series method (equation 1). So, we vary l to switch between the two methods, continually calculating a parameter correction da that we apply to our most recent guess for the parameter vector. The steps that are taken in the LM algorithm are as follows:
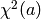
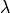 (0.001 in CurveExpert)
(0.001 in CurveExpert)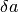
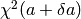
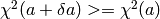 , increase by a factor (10 in CurveExpert) and go back to step [3].
, increase by a factor (10 in CurveExpert) and go back to step [3].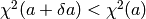 , decrease by a factor (10 in CurveExpert), correct the parameter vector by
, decrease by a factor (10 in CurveExpert), correct the parameter vector by 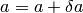 , and go back to step [3].
, and go back to step [3].Iteration is stopped when 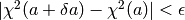 . This
tolerance
. This
tolerance  is the value specified in the File|Preferences dialog.
is the value specified in the File|Preferences dialog.
All nonlinear regression algorithms require initial guesses to commence the search for the optimum regression parameters. As long as AutoGuess isenabled, CurveExpert normally will calculate initial guesses for all built-in nonlinear regressions (linear regressions do not require initial guesses) for you automatically. However, in the case of a poorly performing curve fit, you might want to set these initial guesses manually. Also, you must set these initial guesses manually if you are using a user-defined nonlinear regression model.
In many cases, the physical interpretation of the individual parameters in a regression model may not be clear; hence, an inordinate amount of time can be spent simply trying to obtain appropriate initial guesses. To facilitate this process, CurveExpert provides a dynamic view plot which adjusts itself every time you adjust the initial parameters. This allows you to see the behavior of the curve, and adjust the parameters by hand in such a way that the curve is fairly close to the data points. To display this plot, simply click the Show Plot button. Subsequently, any changes you make to the initial guesses will be shown immediately on the dynamic view plot.
Hint: The plot drawing speed is increased automatically by CurveExpert; it increases the “Resolution” parameter. To increase speed even more, right click on the plot window, choose “Attributes” off of the popup menu, and increase the “Resolution” parameter further.
The initial guess window is shown below:

To ensure that the meaning of the parameters is clear, this display shows you the equation for the model that you are providing initial guesses for.
CurveExpert implements five different types of regression weighting schemes, so that you have a range of methods to choose from. Weighting allows the user to define how much influence each data point will have on the final set of fitted parameters; a large weight denotes that a particular point influences the parameters more (pulls the curve toward itself strongly), and a small weighting on a data point decreases its effect on the parameters. Select “Tools|Weighting Schemes” to pick the weighting to use for a particular curve fit. Only one can be selected at a time; the currently selected scheme is denoted by a check in the menu mentioned above.
The particular type of weighting used in a curve fit is reported in the Graph Information page of the Graph Properties dialog. Also note that weighting only has influence on regressions; any item from the Interpolation menu will not be affected by weighting, since (by definition) interpolations must go through each data point. The types of weighting offered by CurveExpert are the following:
The regression is performed as is, and no weighting is applied during the curve fitting process. This is the most common type of regression analysis; each point has equal influence on the final converged curve. No weighting is equivalent to weighting each data point by 1.0.
The regression is weighted based on the supplied uncertainties in each data point. The uncertainties (in the STD column in the built-in spreadsheet) are interpreted as one standard deviation around the data point. So, during the regression, the calculation will be weighted by
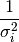
The data points with high uncertainty will contribute less to the converged curve, and data points with low uncertainty will contribute more. This menu choice is not available if CurveExpert detects that no standard deviation data is present in the built-in spreadsheet. Also, if a file that has standard deviation data is read in, CurveExpert automatically selects uncertainty weighting for you.
This type of weighting is rarely used, but weights each data point by the inverse of its x value. Be wary to *not* use this type of weighting when negative x data exists in the data set.
This type of weighting is rarely used, but weights each data point by the inverse of its x value squared. The farther the point is from x=0, the less influence it will have in the final parameter set. This type of weighting is sometimes used when it is known that the uncertainty is a percentage of the independent variables value.
This type of weighting is rarely used, but weights each data point by the inverse of its y value. Be wary to *not* use this type of weighting when negative y data exists in the data set.
This type of weighting is sometimes used when uncertainties in each data point are not known, but when the uncertainty tends to be a percentage of the measured y value. The larger the y value is, the less weight a particular point has.
CurveExpert implements four types of spline interpolation: linear/quadratic/cubic splines, and tension splines.
Warning
The data must be sorted for spline interpolations to complete successfully. To sort your data, choose Data|Manipulation from the main menu and select the “Sort” tab.
Linear splines are the simplest form of spline – they simply approximate the range between data points by a straight line. The purest definition of a linear spline is that is simply ensures that each discrete spline matches the data points. These splines are simply a “connect-the-dot” approach that can be useful in increasing the resolution of a given table of values by using linear interpolation between each point. However, if this is the application, cubic splines provide a much more accurate representation between the data points.
Note also that the data must be sorted for the spline operation to complete successfully. To sort your data, choose Data|Manipulate and select the Sort tab.
Quadratic splines interpolate the range between data points by a 2nd order polynomial (quadratic). Quadratic spline curve fitting ensures that each spline is equal to the data points, and that the 1st derivative of the splines are continuous, even at the knots. Quadratic splines perform better than simple linear splines, but are often characterized by “swinging” too high or too low past the data points.
Quadratic splines must have one free condition specified for the first spline. CurveExpert follows common practice, which is to specify that the 2nd derivative of the first spline is zero – this has the effect of connecting the first and second points with a straight line.
The implementation of quadratic splines used in CurveExpert requires a good deal of memory and crunching time (even more than that of the cubic spline). Do not use this curve fit on an excessive number of data points! Use caution when applying this class of splines.
Note also that the data must be sorted for the spline operation to complete successfully. To sort your data, choose Data|Manipulate and select the Sort tab.
Cubic splines interpolate the range between data points by 3rd order polynomials (cubics). Cubic spline curve fitting ensures that each spline is equal to the data points, the 1st derivatives are continuous at the knots, and the 2nd derivatives are continuous at the knots. Since discontinuities in 3rd and higher derivatives cannot be visually detected, cubic splines have an “aesthetically pleasing” appearance. In fact, cubic splines mimic the behavior of drafting splines used in olden days. Various end conditions can be used for cubic splines. Common practice is to use “natural” end conditions by specifying that the 2nd derivative of the end splines are zero at the endpoints. This gives the visual appearance of “straightening out” at the ends, which is the behavior of a physical drafting spline. This behavior is the type implemented in this version of CurveExpert. Note also that the data must be sorted for the spline operation to complete successfully. To sort your data, choose Data|Manipulate and select the Sort tab.
Tension splines behave similarly to cubic splines, with the addition of a parameter (the tension) which specifies how “tightly” the spline forms to each knot. A low tension parameter will yield a spline similar to a cubic spline; whereas at high tension, the spline will approach a linear spline. The Set Tension dialog box allows you to set this parameter before the tension spline curve fit is performed. You can experiment with the tension to obtain the visual quality that you want in your spline.
Note that there is no easy way to specify a tension spline, except by creating a table of its values. It is also very ill-behaved – expect a few complaints from CurveExpert about floating point errors. To alleviate this type of error, make sure that your data is scaled to an order of one, and give intermediate tension parameters (0.1 to 20).
Note also that the data must be sorted for the spline operation to complete successfully. To sort your data, choose Data|Manipulate and select the Sort tab.
Warning
The data must be sorted for spline interpolations to complete successfully. To sort your data, choose Data|Manipulation from the main menu and select the “Sort” tab.
Lagrangian interpolation is simply interpolating the data set with a polynomial. The order of the polynomial is determined by the number of points in the data set – the polynomial must have enough degrees of freedom to fit the data set at every point. Therefore, in a data set with n points, the interpolating polynomial will be of n-1 degree.
Lagrangian polynomials are particularly well suited for data sets with a low number of data points (8 or less). Preferably, the data points should not have too much scatter. Like all polynomials, the Lagrangian interpolating polynomial exhibits more oscillatory behavior as the degree increases. Therefore, the use of Lagrangian interpolations should be avoided if the number of data points is large. Currently, CurveExpert limits the use of this type of interpolations to data sets with 13 points or less. As the name implies, extrapolating beyond the scope of the data points with an interpolating polynomial can be very detrimental. Interpolations only provide accuracy between the data points – using them to obtain y data outside of the range of the data points must be done very carefully.
Note also that the data must be sorted for the interpolation to complete successfully. To sort your data, choose Data|Manipulate and select the Sort tab.
Using the built-in CurveFinder essentially does all of the hard work for you. You provide the data file, and the CurveFinder does the rest. It sifts through every possible curve fit, ranks the fits from best to worst, and presents you with the best one. Choosing CurveFinder from the Data menu will invoke a dialog box that will ask you for input on which families of regression models to search. Also, you may use the “all on” and “all off” buttons to check or uncheck all of the families at once. See Regression Models and Linear Regression for details on each built-in model. If the polynomial family is included for consideration, you must specify the maximum degree of the polynomial that CurveFinder will consider in the “Polynomial Constraint” area. Of course, if the polynomial family is not included, the polynomial constraint will simply be ignored.
Once you are finished selecting which model families CurveFinder should search, press the OK button. The calculation will then proceed, and each curve fit is ranked according to its standard error and correlation coefficient (see the Data Modeling with CurveExpert section for the appropriate equations), and the best fit is then displayed in the graphing window. Thats all there is to it!
Note that CurveFinder considers ONLY regressions (linear and nonlinear) in its search for the best fit. Further, as described above, you can select only certain families to be considered in the search for the best curve fit. See Regression Models for a description of the model families. Interpolations are guaranteed to pass through each of the data point, so an evaluation of their performance relative to a regression-type curve fit is rather difficult. Therefore, interpolations are excluded from the CurveFinders search; however, you may still decide to try these curve fits manually when CurveFinder is done.
This dialog will automatically generate initial guesses for the nonlinear regression models, whether AutoGuess is enabled or not. If a particular curve fit diverges or generates a floating point exception, it is excluded from the calculation process. In the case that an important curve fit in the group is not calculated, you must select that curve fit manually from the Apply Fit menu and adjust the initial guesses, if necessary.
The CurveFinder dialog is shown below:

The Calculate Groups dialog allows you to automate the process of finding the right data model. This option is most helpful when you have data that follows a certain trend that matches a particular model family or families. Using Calculate Groups, you can select those families that you would like to see, and CurveExpert will automatically calculate all of the curve fits in that group, rank them on the main windows ranking chart, and open a graphing window for each of the curve fits. See Regression Models for a description of the model families.
This dialog will automatically generate initial guesses for the nonlinear regression models, whether AutoGuess is enabled or not. If a particular curve fit diverges or generates a floating point exception, it is excluded from the calculation process. In the case that an important curve fit in the group is not calculated, you must select that curve fit manually from the Apply Fit menu and adjust the initial guesses, if necessary. The Calculate Groups dialog is shown below:
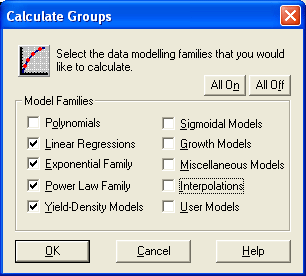
Press this button to select all of the families listed in this dialog.
Press this button to deselect all of the families listed in this dialog.
Click the checkbuttons beside each model family to include them in the calculation. Families that are not marked by an X will not be included.